


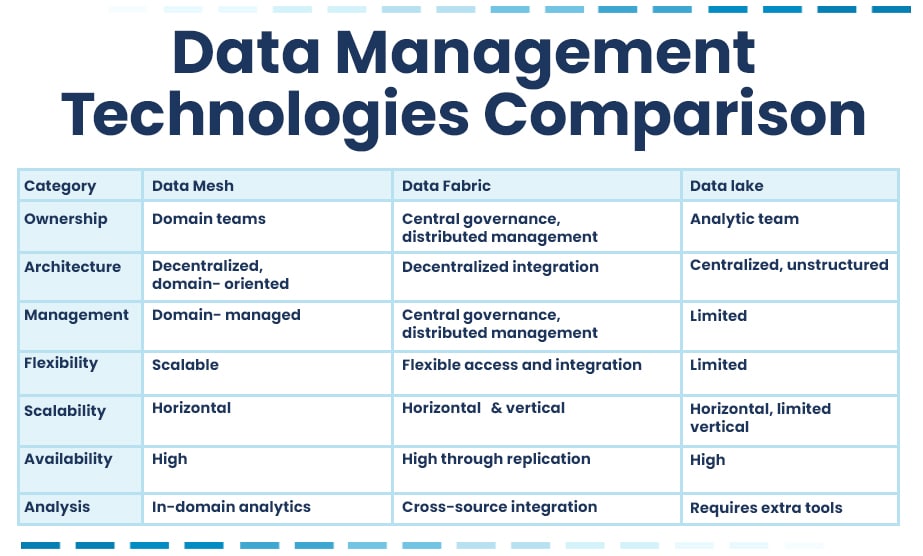
In the modern digital environment, businesses encounter a plethora of hurdles in managing data, primarily stemming from the exponential growth, diversity, and intricate nature of data, alongside the multitude of applications and users seeking access. Foremost among these obstacles is the imperative to adopt an optimal data framework and compatible technologies to align with evolving business demands and data specifications. In this brief article, we will guide you through the essential intricacies of data science: Data Mesh, Data Fabric and Data Lake, presenting their key aspects and benefits.
Let’s first try to explain what a data mesh really is. A data mesh is a decentralized approach to data management, where multiple teams within the company are responsible for their own data, promoting collaboration and flexibility.In other words, Data Mesh focuses primarily on the autonomy of data. It’s a domain-oriented and decentralized approach to data architecture.Key concepts of Data MeshIn Data Mesh, data streams and sets are owned by the users. These are raw, not operational data. They can be transformed to create a shared, aggregated view for a chosen business domain. With Data Mesh, data becomes a product. It has a product team, a product usage map, proper management, and development directions. Data platforms are created, which are a set of patterns, conventions, tools, and infrastructure for storing and monitoring events. This helps data users focus on goals and avoid data silos, which were common in the past. Additionally, Data Mesh allows for the democratization of data access and usage, empowering domain teams to efficiently manage and derive insights from their specific datasets.
Implementation of Data Mesh requires a strategic approach and a deep understanding of both technology and organizational structure. The first step is to define data domains and teams that will manage the data. Then, it’s necessary to establish technological frameworks that will support the Data Mesh model in data analysis, management, and storage, including robust data engineering practices. It’s also important to build an organizational culture that supports collaboration and openness to change. Ultimately, the success of implementing this concept depends on combining the right technical tools with effective management of data teams and business processes.You can read about how to implement Data Mesh step by step here: https://intechhouse.com/blog/data-mesh-implementation-step-by-step-process/

The difference between Data Mesh vs Data Fabric primarily lies in the approach to organizational roles, responsibility for data, as well as the distribution of data ownership and access. Data Meshes help business teams utilize data for analytics and improve data quality, while data fabrics assist the Chief Data Officer and data management team in managing access to connected data sources regardless of where they are stored – including data warehouses or data lakes. Furthermore, data mesh promotes fostering a culture of data ownership and collaboration among domain teams.Defining Data Fabric in data architectureTo understand what Data Fabric is, it’s worth quoting the words of Ivan Batanov, Senior Vice President of Engineering at Crux. As he explains: “Data Fabric is a term used to describe an architecture that involves taking disparate systems and weaving them together, like fabric, to create a cohesive layer on top of an organization’s data.” In other words, the Data Fabric architecture is a more centralized and integration-focused approach to data management. Its goal is to create a unified and cohesive data layer throughout the organization, facilitating efficient data pipeline development and management. The fabric provides a unified view of data across various sources and formats, enabling seamless access and analysis for informed decision-making.

Several factors can aid Data Fabric in ensuring data quality:
By undertaking these measures to uphold data quality, the data fabric becomes more efficient. Additionally, data quality software can significantly assist in elevating data quality.On the other hand in the context of Data Mesh, although data ownership and management are decentralized, governance standards remain centralized. This implies that while individual domains within the organization retain autonomy over their data, there exists a set of overarching governance and quality standards applicable across all domains. Centralized governance standards in the Data Mesh environment play a pivotal role in ensuring that while domains are empowered to manage their data independently, they do so in alignment with overarching objectives, security protocols, quality norms, and requisites.
Data Lake serves as a storage reservoir capable of swiftly absorbing vast quantities of raw data in its original format. This enables business users to promptly access the data as required, while data scientists can leverage analytics to derive valuable insights. Distinguishing itself from its predecessor, the data warehouse, a data lake excels in accommodating unstructured data such as tweets, images, voice recordings, and streaming data. However, it is versatile enough to store any form of data—regardless of its source, size, speed, or structure. Additionally, data virtualization plays a crucial role in seamlessly integrating data from disparate sources, providing a unified view without physical movement or duplication of data.Role of Data Lake in modern data managementThanks to Data Lake, organizations can store data from various sources in one place in its original form, allowing for flexible analysis and utilization of diverse analytical methods. To serve as a robust business intelligence hub that delivers significant business benefits, a data lake necessitates integration, purification, data and metadata oversight and governance. Forward-thinking enterprises are embracing this all-encompassing strategy towards data lake administration. Consequently, they access data and leverage analytics to connect varied data from multiple origins and formats. This translates into a richer pool of insights for informed decision-making within the business.
From InTechHouse’s experience, it can be concluded that Data Lake signifies:
Centralization of data facilitates efficient management processes by consolidating data into a single repository, simplifying organization, updates, and ensuring integrity. This centralized approach also enhances data analysis capabilities and enhances decision-making through data-driven strategies. What’s more, typically these central data are much better protected.On the other hand, decentralization empowers individual entities or departments within an organization to independently handle their data. This autonomy fosters innovation by allowing teams to customize data management practices according to their unique requirements. Decentralized systems offer also inherent scalability as data can be distributed across various nodes. Besides, as specialists from InTechHouse emphasize, decentralized data architecture is significantly more resilient to failures.
Data Fabric embodies a governance strategy characterized by a centralized approach. Within this fabric, the management of metadata and virtual layers is consolidated. On the other hand, a Data Mesh architecture represents a decentralized method, where individual domain teams take charge of their own data governance, akin to a grassroots initiative. Whether opting for a fabric or mesh framework, it’s crucial to tailor the governance strategy to align with the risk versus value dynamics specific to the use case. A Data Mesh emphasizes autonomy, granting domain teams the authority to oversee their respective domains. Depending on the nature of the data involved, different domains may adopt varying governance approaches, ranging from stringent controls for high-risk data to more open-access policies for others. This decentralized governance approach enables efficient management and utilization of data across various domains within the organization.On the other hand management of Data Lake Governance encompasses several essential procedures:
Organizations don’t have to choose between these two data visions. InTechHouse knows perfectly how to combine them to extract maximum benefits. Besides, several Data Fabric concepts align with the principles of Data Mesh. For instance, Data Mesh necessitates a comprehensive data catalog for efficient data exploration, a feature that can be facilitated by adopting some of the metadata management techniques inherent in Data Fabric. Moreover, a centralized Data Fabric can coexist alongside a Data Mesh by functioning as a substantial data entity within the broader Data Mesh framework.Benefits of Integrating Data Mesh and Data Fabric:
Embracing both Data Mesh and Data Fabric can revolutionize modern organizations, empowering domain teams to innovate autonomously while streamlining data integration, access, and analysis across the organization. Together, they synergize to drive data-driven decision-making, fuel business growth, and maintain a competitive edge in a data-centric environment.
There is no one correct approach to data. It all depends on the needs of the company, its structure, challenges, and goals. The most important thing is not to blindly follow technological trends but to properly define business objectives and the means to achieve them.At InTechHouse, solutions are always tailored to specific needs. By bringing together software and hardware professionals in one place, we can even execute the most advanced projects.
What is the fundamental difference between Data Mesh, Data Fabric, and Data Lake?Data Mesh emphasizes decentralized data management, empowering individual teams to oversee their own data, while Data Fabric focuses on creating a unified data layer throughout the organization. Data Lake serves as a storage reservoir for vast quantities of raw data, facilitating flexible analysis.What are the key concepts underlying Data Mesh implementation?Data Mesh involves ownership of raw data streams by users, transformation into shared, aggregated views for specific business domains, and treating data as a product with dedicated teams, management, and development directions.How does Data Lake differ from traditional data warehousing solutions?Data Lake excels in accommodating unstructured big data and can store any form of data regardless of its source, size, speed, or structure, providing a more cost-effective and versatile solution compared to traditional data warehousing.What role does Data Lake play in modern data management strategies?Data Lake serves as a centralized storage hub for diverse data types, facilitating flexible analysis and utilization of various analytical methods to derive valuable insights for informed decision-making.How can Data Mesh and Data Fabric be linked within an organization's data strategy?Both concepts can coexist. Integrating Data Mesh and Data Fabric offers a holistic approach to data management that optimizes data accessibility, governance, and scalability. By leveraging the strengths of both frameworks, organizations can achieve greater agility, efficiency, and innovation in their data strategies, ultimately driving business success.
This initial conversation is focused on understanding your product, technical challenges, and constraints.
No sales pitch - just a practical discussion with experienced engineers.
Share a few details about your product and context. We’ll review the information and suggest the most appropriate next step.



